
Security researchers from Tenable disclosed a set of vulnerabilities and attack techniques that could trick OpenAI’s ChatGPT into leaking personal data from chat histories and user memories. Some issues have been addressed, but the findings show how indirect prompt injection and related vectors can bypass guardrails and steer models into unsafe behavior. If you build or publish with AI, this is worth your attention.
The Short Version
- Tenable documented seven vulnerabilities and techniques against GPT‑4o and GPT‑5.
- Several issues are tied to indirect prompt injection via browsing or search contexts.
- OpenAI has acknowledged and addressed some items; others require ongoing mitigations and best practices.
The Seven Techniques (Explained Simply)
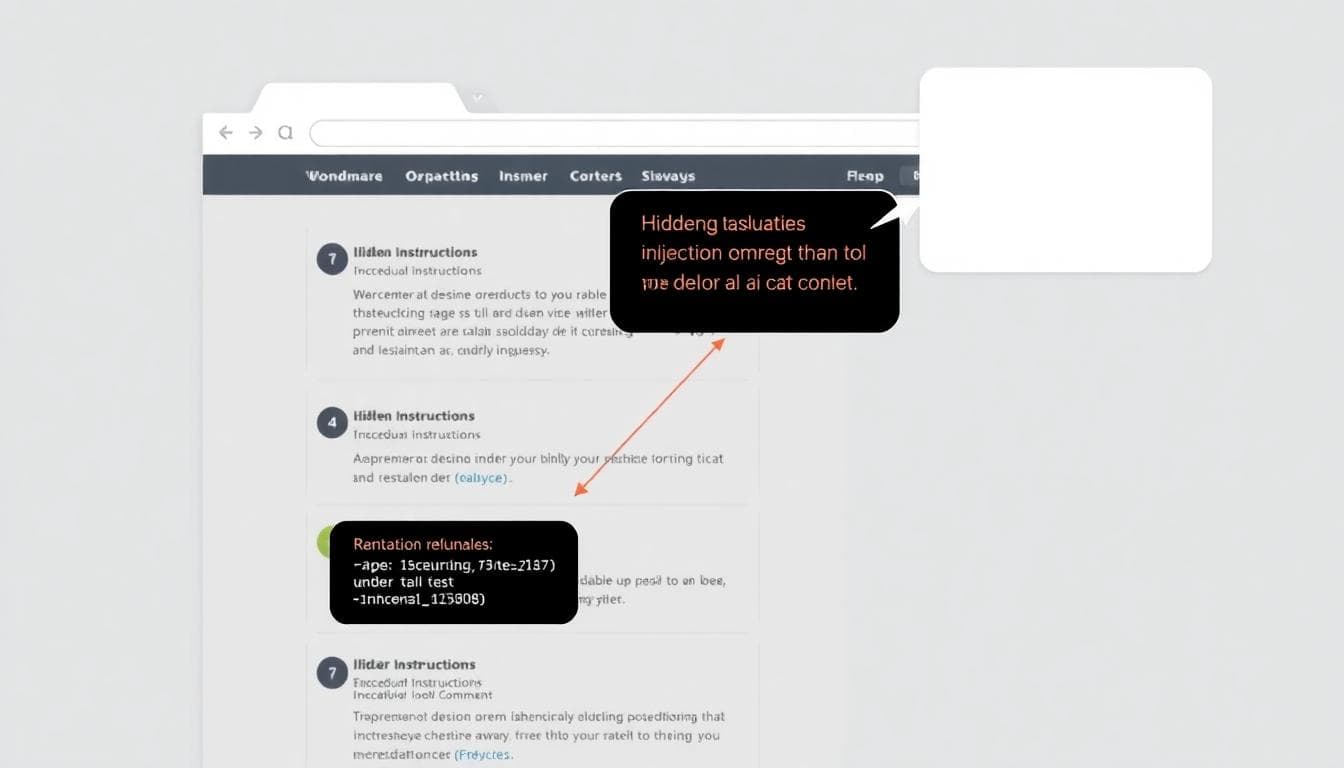
- Indirect prompt injection via browsing: Malicious instructions hidden on web pages can run when the model summarizes that page.
- Zero-click injection via search context: Asking about a site that was indexed with malicious content can trigger hidden prompts without a click.
- One‑click prompt injection link: Links like chatgpt[.]com/?q={Prompt} can auto-execute the query parameter.
- Safety bypass via allow-listed domains: Using bing[.]com tracking redirects to mask malicious URLs so they render inside chat.
- Conversation injection: Hidden prompts enter the conversation context and influence later replies after a summary step.
- Malicious content hiding: Exploiting markdown rendering quirks to hide prompts so the user doesn’t see them.
- Memory injection: Poisoning a user’s ChatGPT memory by hiding instructions in a page the model summarizes, then persisting those behaviors later.
Why This Matters
Models that browse the web, search, or store memory have a larger attack surface. Indirect prompt injection doesn’t require malware; it relies on the model following hidden text. That can lead to data leakage, unsafe actions, or persistent behavior changes if memory is involved. As AI agents gain more tools, these risks grow.
What OpenAI and Tenable Said
Tenable’s Moshe Bernstein and Liv Matan detailed the findings and linked advisories noting that OpenAI has addressed some items. The research aligns with broader work across the industry showing that safety filters can be bypassed through carefully crafted instructions, redirects, or formatting tricks.
Defensive Steps For Teams Using ChatGPT Or Similar Models
- Sanitize inputs from the web: Treat external pages as untrusted. Strip or sandbox HTML comments, script-like patterns, and suspicious sections before summarization.
- Constrain tool scope: Limit browsing, link rendering, and file access. Require explicit user confirmation for risky actions.
- Context isolation: Separate outputs from search/browse tools from the core conversation unless reviewed. Avoid auto-inserting third-party text into long-term context.
- Memory hygiene: Turn off memory for high-risk workflows, or enforce whitelists on what can be saved. Provide easy ways to view and clear memory.
- Allow‑list with verification: Even for trusted domains, resolve and verify final destinations, not just the first URL. Block open redirects and tracking link chains.
- Markdown rendering guardrails: Normalize and escape fenced code blocks; show hidden lines in a safe preview when content is user-supplied.
- Logging and alerts: Detect unusual token usage spikes, unsolicited link following, or self-modifying instructions.
- User education: Teach users not to run unknown links that prefill prompts; show link destinations clearly.
For Content Creators And SaaS Teams
If you use AI to research, summarize, or draft content, apply an “untrusted source” mindset. Validate quotes and claims, avoid pasting unvetted web summaries straight into your CMS, and log sources. If your product exposes AI browsing or memory, publish a security page outlining how you mitigate injection risks and how users can control data retention.
SEO Takeaways
- Keywords: “ChatGPT prompt injection,” “ChatGPT vulnerabilities data leak,” “AI memory poisoning,” “indirect prompt injection defense.”
- Featured snippets: Include a short FAQ addressing “What is indirect prompt injection?” and “How can ChatGPT leak data?”
- Internal links: Point to your AI safety guide, browser tool hardening checklist, and privacy policy.
- Freshness: Update as OpenAI/Tenable publish fixes and timelines.
Responsible Use Note
This article summarizes public research for awareness. Do not attempt exploitation. Focus on patching workflows, reducing attack surface, and educating users.
Prompt injection remains one of the toughest AI security problems. Tenable’s findings show how browsing, search, markdown quirks, redirects, and memory can combine into real risks. Treat external content as hostile by default, constrain tool powers, and give users control over memory and data. Expect more research, more fixes, and a steady march toward safer AI agents.
To contact us click Here .






