
Microsoft faced a significant service disruption on Wednesday, just hours before its scheduled quarterly earnings release. The outage affected Azure cloud services and parts of Microsoft 365, with users reporting issues accessing websites, apps, and company pages. Reports began surfacing around late morning Eastern Time, and Microsoft confirmed it was investigating issues linked to Azure Front Door, a core content delivery and routing service.
What happened
Microsoft indicated the disruption was tied to Azure Front Door. Customers and Microsoft-run properties saw latency, timeouts, and error responses. As is common during broad network events, the effects varied by region and workload. Microsoft stated it suspected an inadvertent configuration change triggered the incident. The company said it initiated a rollback to the last known good state to stabilize traffic and begin node recovery.
On social media and status pages, Microsoft support teams noted that multiple services were impacted. Xbox and investor relations pages were intermittently unavailable. Microsoft 365’s status channel flagged downstream issues tied to the Azure incident. While not all tenants were affected, many organizations reported service degradation for apps that rely on Azure edge and routing layers.
Why Azure Front Door matters
Azure Front Door handles global load balancing, edge routing, and acceleration for web apps and APIs. When it encounters configuration or deployment problems, customers can see widespread effects. That includes longer load times, connection failures, and session errors. Because many Microsoft cloud products depend on the same edge and routing layers, an issue here can cascade into Microsoft 365 experiences like Outlook on the web, SharePoint, or Teams sign-ins.
Timing complicates investor focus
The outage landed only hours before Microsoft’s earnings call. Cloud stability, AI demand, and Copilot monetization have been top topics for investors. A service disruption near earnings can heighten scrutiny on reliability and change-management practices. Microsoft communicated that it was rolling back the triggering change and routing traffic through healthy nodes, with signs of recovery expected as the rollback progressed.
Knock-on effects for customers
Some airlines and consumer brands reported service disruptions for their web properties due to the Azure issue. When a provider’s edge layer encounters trouble, customer-facing sites and booking systems can slow, break, or time out. For businesses with high transaction volume, even short outages can lead to revenue impact, support volume spikes, and SLA questions.

Context: a competitive cloud week
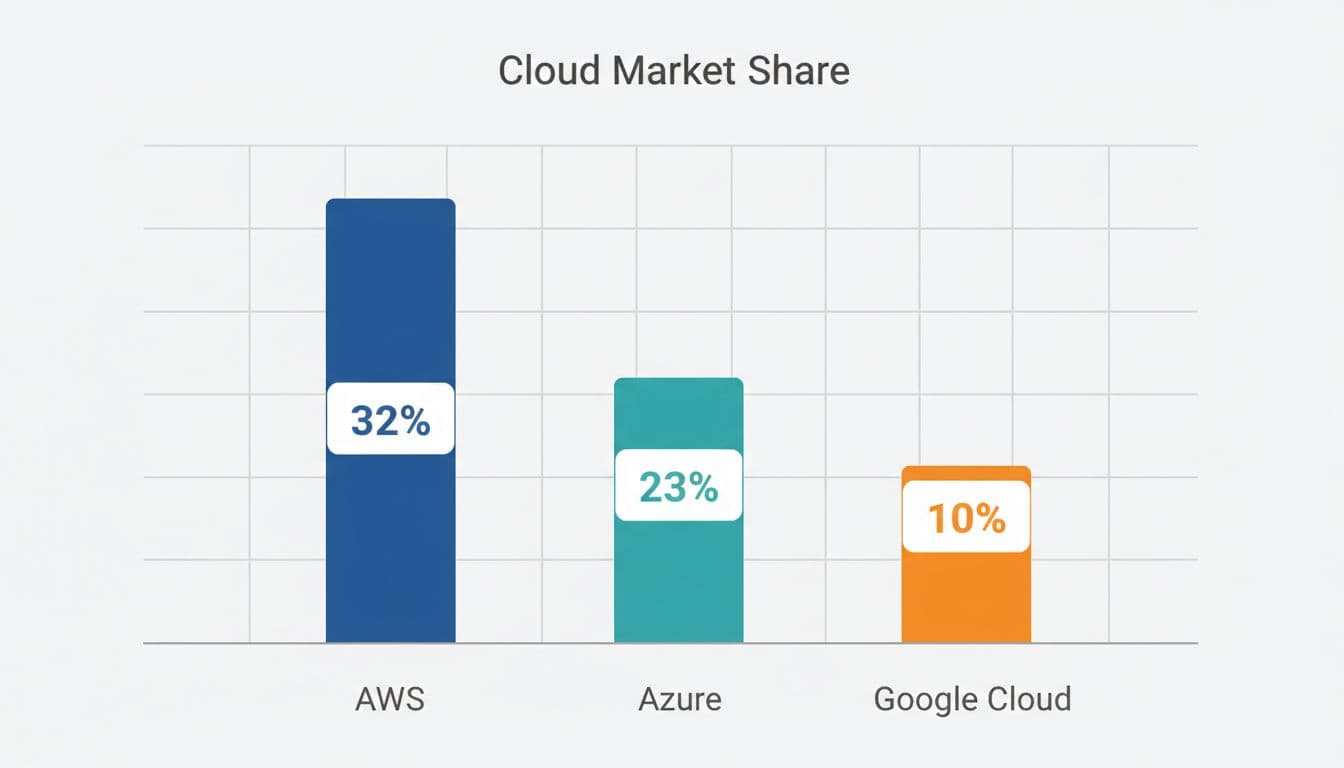
This incident comes amid a packed earnings week for major cloud providers. Amazon Web Services recently dealt with a separate outage that affected customer launches and operations. Market share data shows AWS leading in infrastructure with roughly one-third of the market. Microsoft Azure holds the second position, with Google Cloud trailing. All three have been growing usage in AI-related workloads, which further raises the stakes for uptime and performance.
What Microsoft communicated
- Root cause: Microsoft suspected an inadvertent configuration change affecting Azure Front Door.
- Mitigation: Rollback to a known good configuration and staged node recovery.
- Customer guidance: Monitor the Azure Service Health dashboard and service-specific alerts.
- Recovery: Initial signs of improvement were expected as the rollback propagated.
What customers should do next
Technical teams can take several steps during and after an outage:
- Check your tenant’s Service Health dashboard and subscribe to alerts for Azure and Microsoft 365.
- Fail over to secondary regions if your architecture supports it, and validate DNS or traffic manager policies.
- Reduce nonessential background jobs, retries, and batch processes to lighten load during recovery.
- Enable user-friendly error handling in apps to limit churn and support tickets.
- Review post-incident logs, latency trends, and timeout thresholds; tune backoffs and circuit breakers.
- Document lessons learned and update runbooks for future configuration rollback events.
SEO and comms tip for site owners
If your site went down during the outage, publish a short status update on your blog or status page. Use clear language, include a precise timestamp, and state what users may still experience. Add structured data for articles and post to your main social channels to inform users and reduce support volume. For search, keep your permalink stable and update the post as recovery progresses to create a single source of truth.
What to watch after the outage
- Microsoft’s post-incident report and any commitments around change controls or deployment safeguards.
- Updates on Azure Front Door resiliency, canary practices, and rollback automation.
- Short-term customer impacts on SLAs, credits, or remediation steps.
- Any commentary on the earnings call about reliability, AI workload growth, and edge capacity.
Outages happen, even for the biggest cloud providers. The key questions are how quickly the provider detects the issue, whether rollback procedures work as designed, and how clearly they communicate. Microsoft identified the likely trigger, initiated a rollback, and began node recovery. Customers will look for a transparent post-incident review and pragmatic steps that reduce the chance of similar configuration errors affecting the edge again. With AI demand rising and more apps relying on global routing layers, reliability at the edge is now a core product KPI, not just an infrastructure detail.
To contact us click Here .






